Hace unas semanas estaba armando un RAG: un sistema que recupera documentos para responder preguntas con un modelo. La especificación era clara en la parte del negocio: qué preguntas tenía que responder, qué campos usar y cómo fragmentar la información. Lo que no estaba definido era la elección del modelo de embeddings, que produce la representación vectorial con la que el sistema decide qué documentos se parecen entre sí. El copiloto avanzó con la implementación y eligió MiniLM, un modelo liviano de embeddings. No me detuve a cuestionarlo: sonaba razonable, el código estaba prolijo, los tests pasaban.
Semanas después, el sistema estaba entregando respuestas pobres de manera consistente. El diagnóstico técnico fue rápido: recall muy bajo, es decir, la recuperación traía pocos de los documentos relevantes. El modelo de embeddings no distinguía bien entre documentos que para un humano eran claramente distintos. MiniLM es un modelo legítimo, útil en muchos contextos. Para ese RAG era demasiado liviano, pero esa evaluación no la había hecho. No fue un bug. Fue una decisión técnica que el copiloto propuso y yo simplemente acepté.
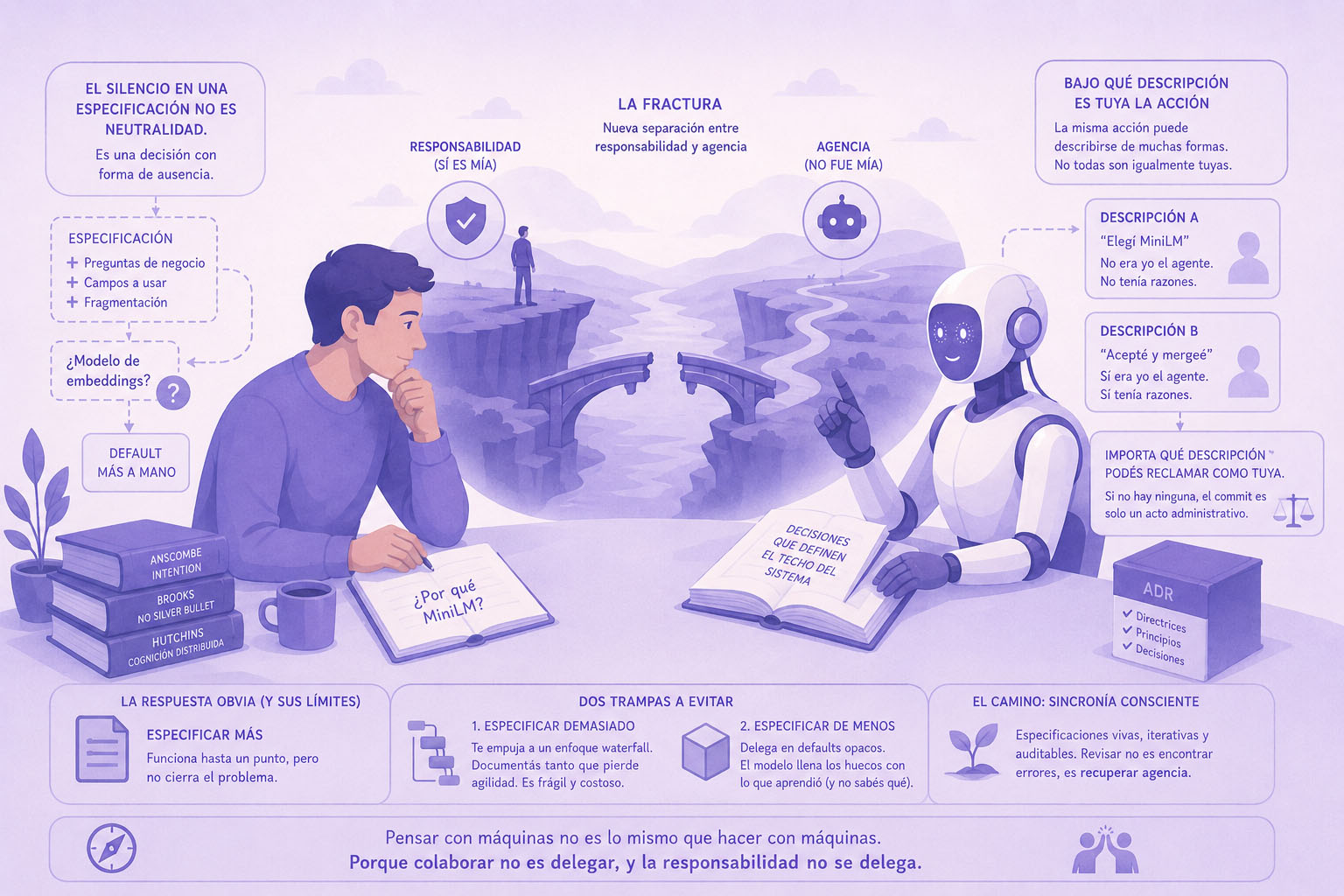
La fractura
La reacción natural frente a una anécdota así es: “faltó especificar”. Es correcta, pero tibia. Esconde la parte interesante.
Hay una fractura nueva entre responsabilidad y agencia. El sistema era mío; la responsabilidad también. La elección de MiniLM no era mía en ningún sentido fuerte. Si alguien me hubiese preguntado minutos después de mergear, “¿por qué elegiste MiniLM?”, no tenía respuesta. Lo acepté porque estaba ahí, prolijo, ejecutándose. Pero el techo del sistema lo decidió esa elección, no cualquiera de las decisiones que sí tomé yo.
Esa fractura no aparece por accidente. Es una propiedad nueva del trabajo con copilotos, y se vuelve sistemática a medida que la práctica se mueve hacia el desarrollo guiado por especificación (spec-driven development). Ahí es donde la ética del oficio se vuelve interesante: no en aceptar código que no leíste (ese problema es viejo, solo cambió de escala), sino en responder por sistemas cuya forma concreta no elegiste.
El silencio en una especificación no es neutralidad. Es una decisión con forma de ausencia. Y como toda decisión, desplaza agencia: si vos no la ejercés, la ejerce el proceso que llena el hueco. En este caso, el modelo que completó el silencio con el default más a mano.
Bajo qué descripción es tuya la acción
La filósofa inglesa Elizabeth Anscombe propuso en Intention (1957) una distinción que sirve como cuchillo. Una acción es intencional bajo una descripción. La misma acción puede describirse de muchas formas, y no todas son igualmente tuyas. Si alguien está bombeando agua a una casa, su acción puede describirse como “bombear”, “mover el brazo”, “hacer ruido” o “envenenar a los habitantes” (si el agua tiene veneno). Qué descripciones son intencionales depende de cuáles puede asumir el agente dando un “por qué” inteligible.
Aplicado a MiniLM: bajo la descripción “elegí MiniLM”, no era yo el agente, no tenía razones, no podía explicar por qué ese modelo y no otro. Bajo la descripción “acepté la implementación y mergeé”, sí lo era. Pero las consecuencias del sistema, el recall bajo, las respuestas pobres, fluyen de la primera descripción, no de la segunda. Responsabilidad bajo una descripción, falta de agencia bajo la otra. Antes estas dos cosas se superponían en el acto de escribir código. Ahora, a veces, no.
Entonces no alcanza con haber firmado el commit. Importa bajo qué descripción podés reclamar como tuya una decisión que el modelo resolvió por vos. Si no hay ninguna, la firma en el commit es un acto administrativo, no un acto de autoría.
La respuesta obvia y por qué no alcanza
La respuesta obvia es especificar más. Funciona hasta un punto.
En otro proyecto teníamos un ADR, un registro de decisión arquitectónica, bajado al copiloto como guía para toda tarea de implementación. Dos directrices estructurales (no cosméticas): dejar registro de cada cambio en un changelog, y usar siempre el ORM —la capa de acceso a datos—, nunca operaciones directas contra la base de datos. El copiloto incumplió ambas. A veces generaba migraciones sin agregar la entrada al changelog. A veces escribía SQL directo. No todas las veces, no sistemáticamente, pero sí con suficiente frecuencia como para que cualquier revisión de superficie dejara pasar alguna.
Es tentador atribuirlo a un problema coyuntural: los modelos van a mejorar en seguimiento de instrucciones, y parte de la indisciplina actual se va a corregir con mejores modelos y mejor contexto. Pero hay una parte estructural que no depende solo de modelos mejores. El lenguaje natural tiene ambigüedades que el modelo resuelve probabilísticamente, y esa resolución no es auditable desde afuera. “Siempre usá el ORM” deja espacio: ¿qué pasa con una consulta compleja? ¿qué pasa si el ORM tiene un bug conocido? El ADR no cubre todo; los intersticios los llena el modelo con sus propios defaults.
La moraleja simple, “especificá más”, no cierra el problema. También te lleva a una trampa.
Las dos trampas
Llevar la especificación al punto de clausurar todo el diseño te devuelve, por otra vía, a una lógica waterfall: intentar cerrar el diseño completo antes de construir. Escribís tanto que para cuando terminás, podrías haber escrito el código directamente. Perdiste el valor del copiloto y ganaste una ceremonia de documentación. Especificaciones exhaustivas, además, son frágiles: el mínimo cambio de requerimiento obliga a reescribir capítulos.
Especificar de menos delega en defaults opacos. El modelo llena los huecos con lo que aprendió durante su entrenamiento, y lo que aprendió es una mezcla de buenas prácticas reales, malas prácticas populares, convenciones de frameworks específicos y decisiones de diseño de terceros. Alguien eligió, pero no fuiste vos.
El oficio nuevo, el que hay que aprender, es saber qué tiene que ser explícito y qué puede quedar implícito sin delegar. Eso no sale de un checklist. Es una forma de criterio técnico aplicado a la especificación: saber qué decisiones cargan realmente el peso del sistema y cuáles son cosméticas.
El problema es que este oficio todavía no está bien nombrado. Se nombra mucho la productividad del copiloto, las métricas de generación de código, la velocidad. Se nombra poco el discernimiento sobre qué especificar y qué no. Y lo que no se nombra queda fuera de la formación del oficio.
La paradoja aparente
Hay algo que parece una paradoja debajo del discurso del 10x. Si especificás con rigor suficiente para ser responsable de las decisiones reales, hiciste vos el trabajo intelectual principal. El copiloto implementó, tradujo, formateó, pero las decisiones difíciles las tomaste. Visto así, parece que la ganancia del copiloto se achica cuanto más responsable querés ser.
Es una paradoja solo si medís productividad como velocidad de output. Si medís líneas por hora, tokens generados, tickets cerrados, entonces sí: cuanto más rigurosa tu especificación, más trabajo hiciste vos y menos te “ahorró” el copiloto. Esa es la métrica que el discurso del 10x usa, y es la métrica equivocada.
Medir productividad real exige mirar cuánta de la complejidad esencial —en el sentido de Brooks en The Mythical Man-Month— queda resuelta con criterio y cuánta queda librada al azar. Medida así, la relación se invierte: la especificación rigurosa es donde el copiloto entrega más valor, no menos, porque absorbe toda la capa de producción (traducir intención a sintaxis, implementar patrones, generar tests repetitivos, ajustar detalles mecánicos) mientras el criterio queda en manos de quien puede ejercerlo.
La paradoja se disuelve y deja algo más incómodo: la industria está optimizando para una métrica que no mide lo que importa. Velocidad de output sin criterio es movimiento sin dirección. Se siente como progreso porque las cosas salen, pero el techo del sistema queda definido por decisiones que nadie asumió.
Mientras las métricas midan output y no criterio ejercido, la ética del oficio va a quedar en desventaja. Lo que no se mide, no se valora, y lo que no se valora, no se cultiva.
El hueco de verificación
Supongamos que hacés todo bien. La especificación es rigurosa, el ADR es claro, las dos trampas quedaron esquivadas. Queda un último hueco: ¿cómo verificás que el modelo implementó tu intención y no su interpretación de tu intención?
Los tests cubren comportamiento, no intención. Pasar todos los tests es necesario, no suficiente: un sistema puede pasarlos y seguir siendo el sistema equivocado, si los tests no capturan alguna propiedad que querías y olvidaste codificar. El code review puede cubrir semántica, pero solo cuando la intención está disponible: en una especificación, en una conversación, en el dominio compartido del equipo o en tests que la codifiquen. Cuando esa intención no está disponible, el review tiende a cubrir estructura, consistencia local y plausibilidad. Podés aprobar un código bien escrito que implementa algo distinto a lo que pediste.
Esto abre una pregunta más grande: si el código generado llega con decisiones no asumidas, quizá no alcance con revisar diffs como siempre. Tal vez haya que repensar el code review como práctica de reconstrucción de intención: no solo mirar qué cambió, sino preguntarle al código por qué es así y no de otra manera.
Acá vuelve Anscombe. La firma del PR solo es tuya bajo las descripciones que podés asumir dando razones. Si el código pasa los tests pero no podés narrar por qué cada decisión importante está ahí, lo que firmás no es lo que entendés, es lo que recibiste.
Un paralelo tentador que no aplica
Contra este argumento, alguien con reflejo técnico va a oponer un paralelo que suena bien: “es como cuando pasamos de assembly a lenguajes de alto nivel. Dejaste de elegir registros y el compilador decidía por vos”. Conviene mirarlo de cerca.
El compilador era determinístico y auditable. Con la misma versión y configuración, misma entrada, misma salida. Si querías saber qué había decidido, podías leer el código generado; estaba escrito por reglas que alguien podía inspeccionar. La elección del compilador no era tuya, pero era transparente y estable.
El trabajo con un LLM, en cambio, introduce opacidad y variabilidad. Temperatura, defaults de entrenamiento, contexto que evoluciona, reentrenamientos que cambian las respuestas sin aviso. La elección que hace el modelo no es tuya y tampoco es inspeccionable de manera estable. Dos sesiones pueden producir dos respuestas distintas. Subir un peldaño de abstracción no es lo mismo cuando el peldaño tiene memoria, sensibilidad al contexto y una historia de entrenamiento que no está disponible para quien usa la herramienta.
Tratarlo como una iteración más del mismo movimiento oscurece lo importante: estamos en una estructura diferente, con otra distribución del criterio.
El punto de este artículo no es sugerir que haya que especificar menos. Es reconocer que “especificá más” es una respuesta insuficiente y a veces contraproducente.
Lo que importa es nombrar la fractura entre responsabilidad y agencia como un rasgo nuevo del oficio. Nombrar permite pensar. Y pensar permite decidir en qué casos vale la pena cerrar la fractura pagando el costo en velocidad, y en qué casos aceptarla con los ojos abiertos.
Queda una pregunta que merece su propia conversación: ¿qué rituales organizacionales y qué herramientas (tests como especificación, contratos de tipos, ADRs con tests de conformidad, reviews orientados a reconstruir intención) crean responsabilidad real, no ceremonial, cuando la fractura entre quien decide y quien firma se vuelve sistemática?
Mientras tanto, en la era del copiloto, parte del oficio consiste en decidir qué silencios estás dispuesto a firmar.